
NeurIPS 2024 最佳论文奖:华人作者占据大半江山
重磅干货,第一时间送达

会议之眼 快讯
最近,AI顶会 NeurIPS 2024大会在温哥华正式落幕了,让我们一回顾一下大会精彩。本届共收到15671篇有效论文投稿,录取率为25.8%。华人学者和华人机构表现突出,在4篇最佳论文中,有3篇论文的第一作者是华人。

最佳论文奖(两篇)
(一)《Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction》(视觉自回归建模:通过 Next-Scale预测实现可扩展的图像生成),由北京大学、字节跳动研究者共同完成,论文一作为田柯宇。

论文介绍:
论文提出了视觉自回归建模(VAR),这是一种新的生成范式,它将图像上的自回归学习重新定义为从粗到细的“下一尺度预测”或“下一分辨率预测”,有别于标准的光栅扫描“下一个标记预测”。
这种简单、直观的方法使自回归(AR)变换器能够快速学习视觉分布,并且可以很好地泛化。在ImageNet 256×256基准测试中,VAR显著改进了自回归基线,推理速度快了20倍。
同时,经验验证表明VAR在图像质量、推理速度、数据效率以及可扩展性等多个维度上都优于扩散变换器(DiT)。VAR还进一步展示了在下游任务(包括图像补绘、图像外绘和图像编辑)中的零次学习泛化能力。
这些结果表明VAR初步模拟了大型语言模型的两个重要特性:缩放规律和零次学习泛化能力。
论文地址:https://arxiv.org/pdf/2404.02905
(二)《Stochastic Taylor Derivative Estimator: Efficient amortization for arbitrary differential operators》(随机泰勒导数估计器:任意微分算子的有效摊销),由新加坡国立大学、 Sea AI Lab研究者共同完成,论文一作为Zekun Shi。

论文介绍:
使用包含高维、高阶微分算子的损失函数来优化神经网络时,使用反向传播进行评估的成本很高。
论文展示了如何通过恰当地构建单变量高阶自动微分的输入切线,来对多元函数的任意阶导数张量有效地进行任意收缩,而该方法可用于对任何微分算子有效地进行随机化。
当将其应用于物理信息神经网络(PINNs)时,与采用一阶自动微分的随机化方法相比,该方法实现了超过 1000 倍的加速,并减少了超过 30 倍的内存占用,而且现在能够在单个 NVIDIA A100 GPU 上用 8 分钟求解百万维的偏微分方程。这项工作为在大规模问题中使用高阶微分算子提供了可能性。
论文地址:https://arxiv.org/pdf/2412.00088
最佳论文-亚军(两篇)
(一)《Not All Tokens Are What You Need for Pretraining》(并非所有标记都是预训练所需要的),由厦门大学、清华大学、微软的研究者共同完成,论文一作为Zhenghao Lin。
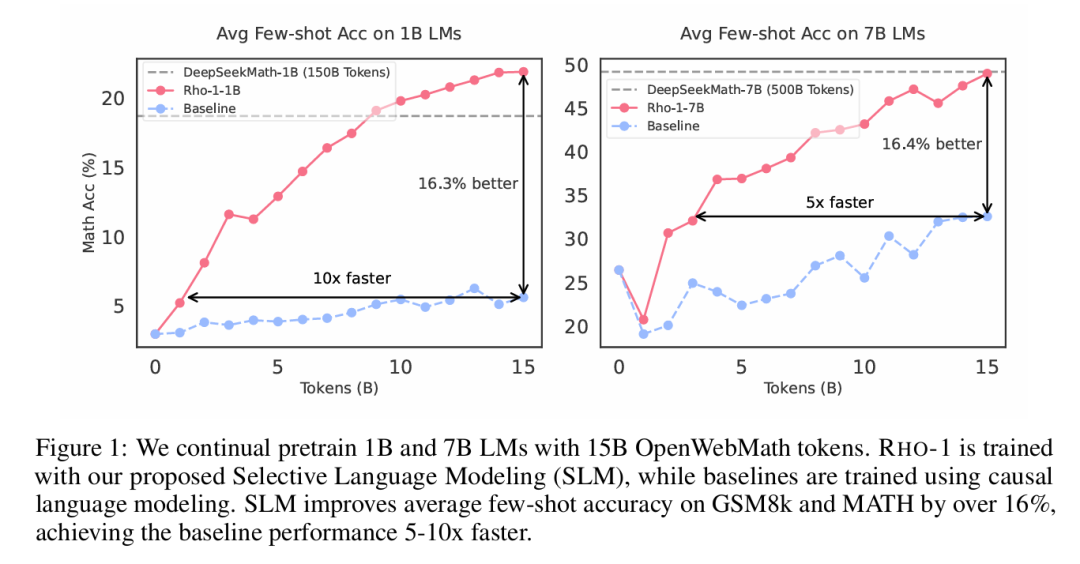
论文介绍:
以往的语言模型预训练方法对所有训练标记均统一应用下一个标记预测损失。作者对这一常规做法提出质疑,并认为“语料库中的所有标记对于语言模型训练并非同等重要”。论文引入了一种名为RHO-1的新型语言模型。
RHO-1采用了选择性语言建模(SLM),它会选择性地针对那些与期望分布相符的有用标记进行训练。RHO-1既提高了语言模型预训练的数据效率,又提升了其性能。
论文地址:https://openreview.net/pdf?id=0NMzBwqaAJ
(二)《Guiding a Diffusion Model with a Bad Version of Itself》(用其自身的不佳版本引导扩散模型),由英伟达、阿尔托大学的研究者共同完成,论文一作为Tero Karras。

论文介绍:
在图像生成扩散模型中,流行的无分类器引导方法在提升文本提示契合度以及提高图像质量的同时,以牺牲多样性为代价。
通过使用模型自身一个规模更小、训练程度更低的版本而非无条件模型来引导生成,有可能在不损害多样性的情况下实现对图像质量的解耦控制。这使得在 ImageNet 图像生成方面有了显著的改进。此外,该方法也适用于无条件扩散模型,能极大地提升它们的质量。
论文地址:https://arxiv.org/pdf/2406.02507
精彩文章回顾
计算机领域为何只认顶级会议论文,而其他领域几乎都是只认可顶级期刊?
CVPR 2024圆满落幕:海报创意不断,学者穿cos服装讨论学术问题?!这届CVPR真是太有趣了
NeurIPS 2024震撼放榜:新纪录诞生,竞争更激烈!
最新全球计算机科学排名揭晓:清华大学登顶CSRankings亚洲榜首!
会议之眼网页端免费使用:https://www.conferenceeye.cn




